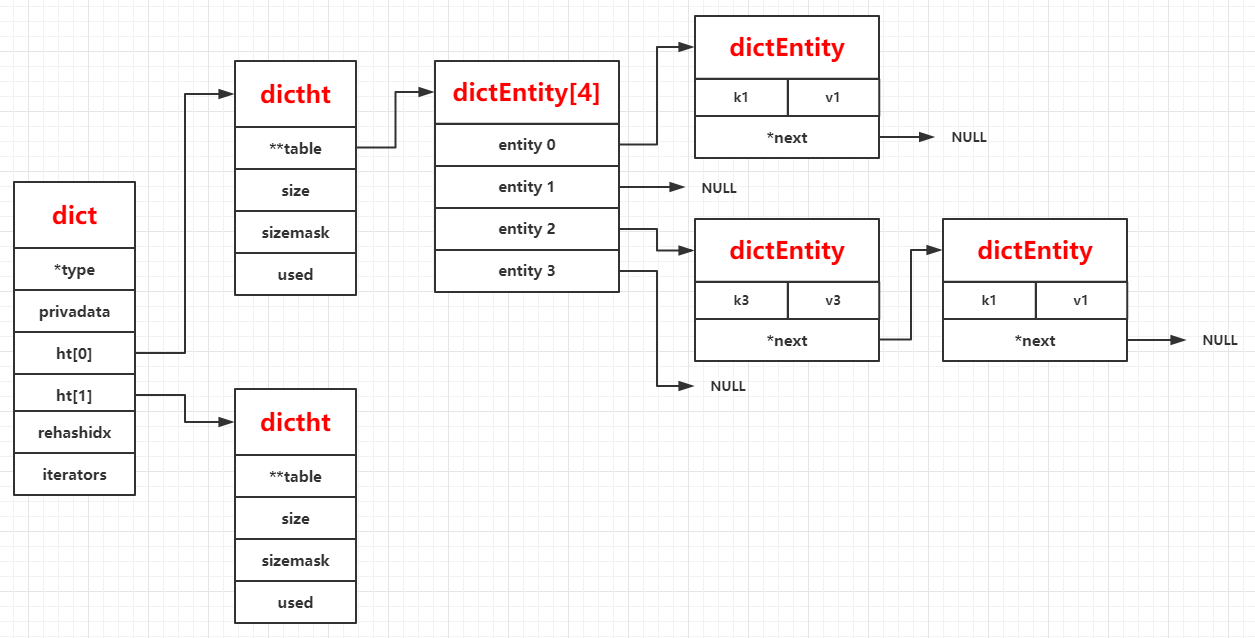
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| dict *dictCreate(dictType *type, void *privDataPtr);
int dictExpand(dict *d, unsigned long size);
int dictAdd(dict *d, void *key, void *val);
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing);
dictEntry *dictAddOrFind(dict *d, void *key);
int dictReplace(dict *d, void *key, void *val);
int dictDelete(dict *d, const void *key);
dictEntry *dictUnlink(dict *ht, const void *key);
void dictFreeUnlinkedEntry(dict *d, dictEntry *he);
void dictRelease(dict *d);
dictEntry * dictFind(dict *d, const void *key);
void *dictFetchValue(dict *d, const void *key);
int dictResize(dict *d);
dictIterator *dictGetIterator(dict *d);
dictIterator *dictGetSafeIterator(dict *d);
dictEntry *dictNext(dictIterator *iter);
void dictReleaseIterator(dictIterator *iter);
dictEntry *dictGetRandomKey(dict *d);
dictEntry *dictGetFairRandomKey(dict *d);
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count);
void dictGetStats(char *buf, size_t bufsize, dict *d);
uint64_t dictGenHashFunction(const void *key, int len);
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len);
void dictEmpty(dict *d, void(callback)(void*));
void dictEnableResize(void);
void dictDisableResize(void);
int dictRehash(dict *d, int n);
int dictRehashMilliseconds(dict *d, int ms);
void dictSetHashFunctionSeed(uint8_t *seed);
uint8_t *dictGetHashFunctionSeed(void);
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, dictScanBucketFunction *bucketfn, void *privdata);
uint64_t dictGetHash(dict *d, const void *key);
dictEntry **dictFindEntryRefByPtrAndHash(dict *d, const void *oldptr, uint64_t hash);
|